
Sapien is a decentralized data protocol focused on producing verifiable human knowledge and high-quality training data for artificial intelligence systems. The project aims to make the data used by AI models more transparent in terms of who produced it, how it was evaluated and how reliable it is.
SAPIEN is the native token of this ecosystem. The token is designed to be used for staking, contributor rewards, quality assurance, the reputation system and governance processes in the future.
At the center of Sapien is a system called Proof of Quality, or PoQ. This structure allows a data output or expert evaluation to be scored by independent validators, turned into a shared quality score and recorded onchain.
For this reason, Sapien is considered not only as an AI coin project, but also as a protocol that aims to reorganize AI data production and verification through blockchain-based incentives.
Sapien’s Definition and Emergence
Sapien defines itself as a “decentralized data foundry.” This can be described as a decentralized data production network or decentralized data factory. The main idea of the project is to organize human contributors from different parts of the world around verified data production that can be used for AI models.
Artificial intelligence systems need large amounts of data. However, data volume alone is not enough. For a model to produce accurate, reliable and contextually appropriate results, the data it uses must also be high quality.
Sapien’s starting point is this problem. The project tries to offer a blockchain-based answer to a question often encountered in AI development processes: “Who produced this data, how was it checked and is it reliable?”
In traditional data labeling and quality control systems, the process is usually managed by centralized teams. In such structures, it is not always clearly visible from the outside how quality standards are determined, how contributors are evaluated and how faulty contributions are filtered out.
Sapien aims to make this model more open, incentive-driven and auditable. Contributors complete tasks, validators evaluate these outputs according to specific rubrics, the system reduces the results to a quality score and the resulting verification record can be stored on the Base network.
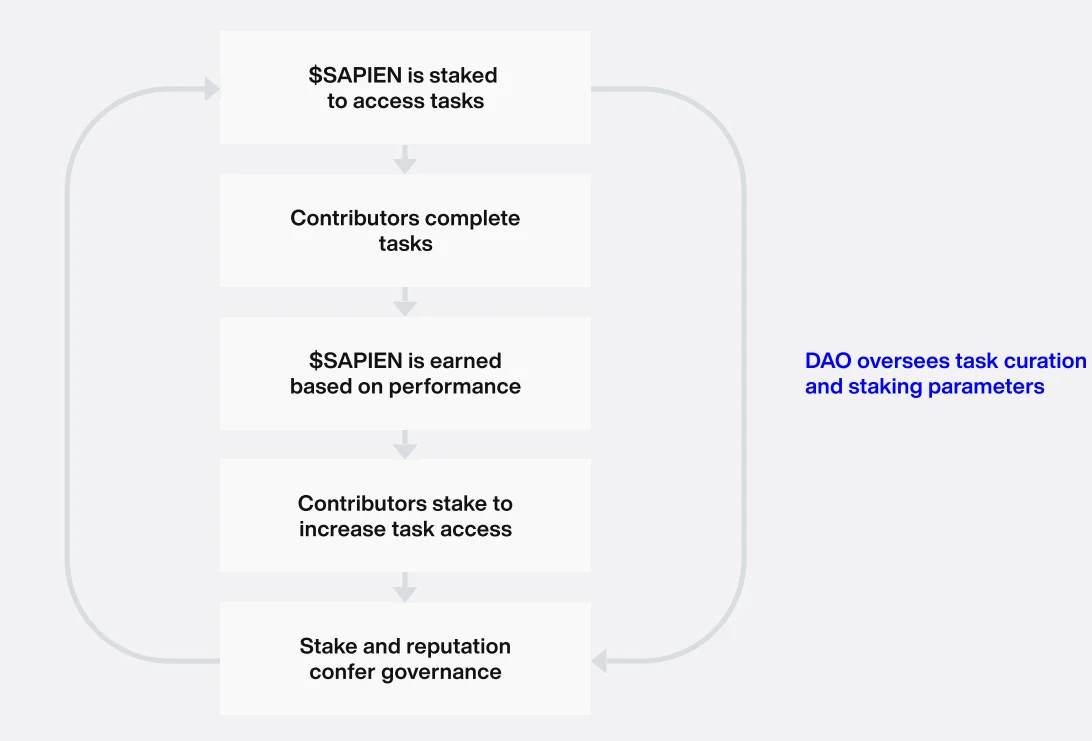
The project’s place in the Web3 ecosystem also becomes clear here. Sapien applies blockchain tools such as staking, slashing, reputation systems, validator systems and onchain attestation to the AI data quality problem.
This approach separates Sapien from a platform that only performs data labeling. The project aims to turn human knowledge into a more reliable, measurable and economically incentivized data layer for AI models.
Sapien’s History: Key Milestones
Sapien’s development process began with early product work focused on the AI data quality problem. The project grew around the idea of making human-contributed data production for AI models more scalable and reliable.
The team behind Sapien consists of people experienced in crypto infrastructure, data systems, product development and AI workflows. The project’s CEO, Rowan Stone, is known for his previous work related to Coinbase and the Base ecosystem. CSO Trevor Koverko is one of the well-known entrepreneurs in the blockchain sector, with a background in Polymath and Polymesh.
In 2024, Sapien attracted attention from the broader crypto and AI community with a $10.5 million seed funding round. This financing process showed that the project was not only a theoretical idea, but also a serious infrastructure initiative aiming to grow within the AI data market.
The year 2025 became a more decisive period for Sapien on the token side. The project published its tokenomics document, clarifying the supply structure, incentive model, staking use and ecosystem role of the SAPIEN token.
The SAPIEN Token Generation Event, or TGE, took place on August 20, 2025. The token was launched in ERC-20 format on Base, Coinbase’s Ethereum Layer 2 network.
In the same period, SAPIEN also began trading on Binance Alpha and Binance Futures. Binance opened SAPIEN on the Alpha side on August 20, 2025, and listed the SAPIENUSDT futures contract.
Later, centralized exchange access for SAPIEN expanded. The token began trading on exchanges such as Coinbase and Kraken. This process helped Sapien reach broader market liquidity.
The Binance spot listing was announced on November 6, 2025. Binance stated that it would open trading for SAPIEN through the SAPIEN/USDT, SAPIEN/USDC, SAPIEN/BNB and SAPIEN/TRY pairs. This listing made SAPIEN more easily accessible to retail investors.
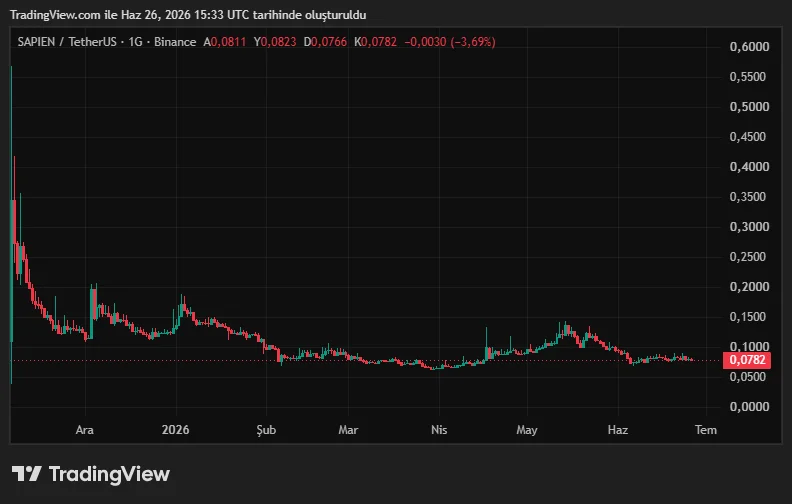
SAPIEN’s price history has shown high volatility since the token entered the market. According to market data, SAPIEN’s all-time high was recorded at $0.5364. As of June 2026, the SAPIEN coin price is around $0.07.
Why Is Sapien Important?
To understand Sapien’s importance, it is necessary to look at the data problem in the artificial intelligence sector. AI models are not only made of code. The quality of these models depends largely on the data sets they are trained on, the accuracy of these data sets and how model outputs are evaluated.
Today, AI models are used across many different areas such as text, images, audio, video, code, medical data, security analysis and robotics. Each of these areas creates different expertise and quality control needs.
General user contribution may be enough for simple data labeling tasks. However, interpreting a medical image, evaluating a security vulnerability or analyzing sensor data from an autonomous vehicle requires a much higher quality standard.
This is where Sapien combines human contribution with economic incentives. Contributors stake SAPIEN in certain cases to be able to perform tasks. This stake acts as a guarantee against quality.
If the contribution is high quality, the user may earn rewards and increase their reputation score. If the contribution is low quality, incorrect or malicious, the system may apply stake loss through slashing.
This structure provides important alignment in AI data production. The contributor is incentivized not only to complete a task, but also to produce high-quality work.
The Proof of Quality system is important for the same reason. PoQ tries to make subjective data evaluations more measurable. An expert output, a model response or a data label is scored by independent validators and converted into a shared quality score.
Recording this score onchain gives the process auditability. This allows an AI team to evaluate the data it uses not only by its raw form, but also together with its verification history.
The area Sapien targets is broad. The project aims to become a quality layer across different use cases such as training data production, LLM evaluation, fine-tuning, RAG source verification, agent decisions, security checks, robotics and autonomous systems.
Sapien’s Technical Structure and Proof of Quality System
At the center of Sapien’s technical structure is Proof of Quality. PoQ is a consensus and attestation system used for subjective data and expert outputs.
To put this system more simply, PoQ tries to measure how reliable an output is. This output may be a data label, a model response, a security finding, a medical evaluation or an expert report.
The process first begins with a task definition. In Sapien’s documents, this structure is called Task Definition Specification, or TDS. TDS determines what a task measures, which inputs it uses, what the quality criteria are and which rubric validators will use for evaluation.
The first stage is called Originate. At this stage, the data set or expert output is entered into the system. The purpose of the task, the expected quality standard and the evaluation rules are defined.
The second stage is the Validate process. At this stage, staked validators evaluate the relevant outputs. Each validator scores the output according to the defined rubric.
Sapien’s official documents state that this scoring process produces a normalized score between 0 and 100. The scores given by different validators are then reduced to a single result through a consensus mechanism.
The third stage is the Attest process. The quality score created as a result of consensus is converted into a cryptographic record. This attestation becomes verifiable on the Base network.
This structure does not mean that the entire data is written to the blockchain. In Sapien’s approach, the data itself may remain within systems, while the verification record and quality signal are carried onchain. This is important for both privacy and scalability.
One of the main mechanisms used by Sapien is the staking system. Contributors can stake SAPIEN to participate in certain tasks or access higher-value tasks. Stake ensures that users take economic responsibility for quality.
The reputation system is also an important part of the technical structure. Users’ task history, accuracy rate, contribution quality and validation performance gradually form a reputation profile. Higher reputation may provide access to more complex or better-rewarded tasks.
Slashing is the system’s discipline mechanism. Low-quality, inconsistent or malicious behavior may be punished with stake loss. In this way, the protocol moves beyond being merely a task platform that distributes rewards and becomes a network that economically protects quality.
This technical structure summarizes Sapien’s main solution to the AI data quality problem. Contributors produce work, validators measure quality, consensus creates a shared score and the result becomes auditable onchain.
What Is the SAPIEN Token and What Is It Used For?
The SAPIEN token is the native crypto asset of the Sapien protocol. The token is used not only for market trading within the ecosystem, but also to operate data production and quality verification processes.
One of SAPIEN’s most basic use cases is staking. Contributors can stake SAPIEN to participate in certain tasks and provide quality assurance to the system. This adds economic responsibility to the work users perform.
The second use case is the reward mechanism. In Sapien, contributors can earn rewards in SAPIEN or USDC by completing tasks. Rewards may vary depending on the user’s performance, stake amount, task type and quality history in the system.
The third use case is connected to the reputation system. In Sapien, simply holding the token is not enough. The user must actually provide high-quality contributions, remain consistent in verification processes and build a reliable profile over time.
This structure separates SAPIEN from a classic reward token. The token is used like working capital within the protocol. Access to tasks, quality assurance, reward earning and future participation in governance processes are shaped around this token.
Sapien’s tokenomics document states that governance may gradually shift toward token holders and a DAO structure. This means SAPIEN holders may play a greater role in protocol parameters, incentive structures and ecosystem decisions in the future.
Another important function of SAPIEN is economic alignment. One of the biggest problems in AI data production is that low-quality contributions can pollute the system. Sapien aims to reduce this problem through stake and slashing.
For this reason, the value of the SAPIEN token is theoretically related to task demand in the network, the number of contributors, the need for verification and the extent to which the protocol is used by AI companies.
SAPIEN Token Economics
The maximum supply of the SAPIEN token has been set at 1,000,000,000. According to the tokenomics document, this supply is fixed and there is no inflationary new mint plan above 1 billion tokens for SAPIEN.
The token runs on Base in the ERC-20 standard. Since Base is an Ethereum-compatible Layer 2 network, it allows SAPIEN to be used with low-cost and scalable onchain transactions.
SAPIEN distribution is divided into several main categories. 13% of the supply is allocated to Seasonal Airdrops, 7% to liquidity incentives and 5% to staking incentives.
The share allocated to backers and investors is 26.82%. The team and advisors receive 20.18%. Contributor rewards receive 15%, while the community treasury receives 13%.
This distribution can also be read under two broad categories. 47% of the supply is allocated to protocol development participants, meaning contributors, developers and early backers. The remaining 53% is directed toward contribution incentives such as task rewards, liquidity incentives, airdrops and the community treasury.
Token unlocks are an important issue in the tokenomics structure. Seasonal airdrops, liquidity incentives and staking incentives were fully unlocked at TGE. Investor tokens and team and advisor tokens are subject to a 12-month lockup followed by 24 months of linear vesting.
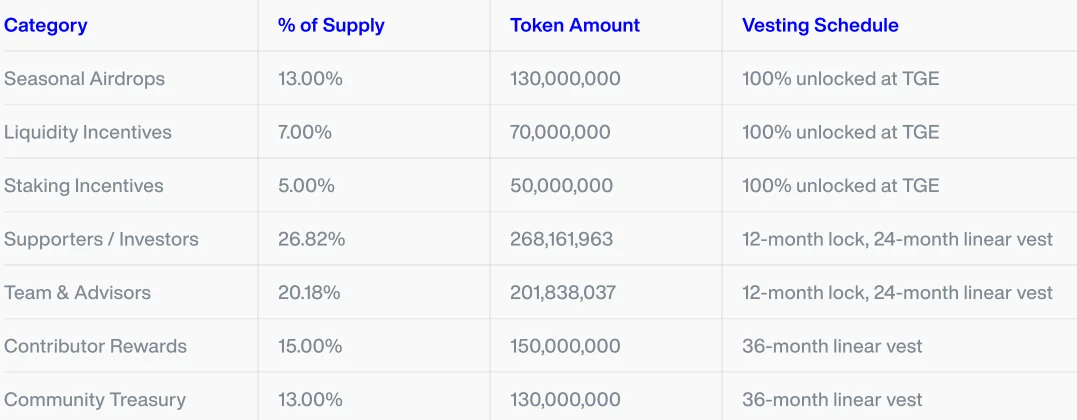
Contributor rewards and the community treasury follow a 36-month linear vesting plan. This structure aims to prevent the token supply from entering the market all at once and to preserve long-term ecosystem alignment.
In Binance’s spot listing announcement, SAPIEN’s circulating supply at the time of its Binance listing was given as 250,000,000 SAPIEN. This amount corresponds to 25% of the total supply.
Sapien’s Use Cases
Sapien’s most direct use case is AI training data production. For AI models to work better, they need high-quality, contextually appropriate and accurately labeled data. Sapien organizes human contributors around this data need.
Data labeling is one of Sapien’s core task areas. Users can perform annotation tasks on text, images, audio, video or more complex data types. These tasks can be used in model training or model evaluation.
LLM evaluation is also an important use case. The responses produced by large language models may not always be accurate, safe or contextually appropriate. Sapien’s PoQ structure makes it possible for model responses to be evaluated by independent experts and connected to a quality score.
A structure similar to Sapien may also be needed in fine-tuning processes. When an AI model is adapted to a specific field, the quality of the preference data and human feedback used becomes critical. Sapien aims to make the source and reliability of this data more traceable.
Source verification for RAG systems is another use case. RAG allows models to generate responses from external information sources. However, whether these sources are reliable is a separate issue. Sapien can provide a trust layer for source quality and human verification.
Data quality is also very important in robotics and autonomous systems. An autonomous vehicle’s ability to correctly perceive its surroundings depends on processes such as 3D data, LiDAR segmentation, object tracking and visual labeling. In these areas, faulty data can affect not only model performance but also physical safety.
Sapien’s official documents describe a quality signal layer that can be used across different stages of the AI lifecycle, such as training data, fine-tuning, evaluation and production. This shows that Sapien is trying to build a system that can be used not only before model training, but also after a model enters production.
Security, audit and compliance areas are also potential use cases for Sapien. Independent evaluation of a security report, model decision or automated agent action may become more important, especially as enterprise AI usage increases.
The common point of these use cases is the need for quality and trust. Sapien aims to move human contribution in artificial intelligence systems away from a random and unaudited process and into a more measurable, rewardable and verifiable structure.
Sapien’s Developers and Community
Behind Sapien is a team experienced in crypto infrastructure, data systems, AI workflows and product development. The project’s company page describes the team as a multidisciplinary structure made up of data, AI and product experts.
Sapien’s CEO is Rowan Stone. Stone played a role in building Base and worked at Coinbase as Director of Onchain Business Development. During his time at Coinbase, he is said to have worked on the growth of products such as cbETH and USDC.
Trevor Koverko serves as Sapien’s CSO. Koverko is known as the founder of Polymath and Polymesh, two projects in the tokenized securities space. He also has experience in crypto staking and market infrastructure through his background with Tokens.com.
Kelly Ryan is Sapien’s CTO. Ryan has experience in scalable products, production systems and human-assisted ML workflows. This role shows that Sapien is not only a token-focused project, but also a technology company trying to scale operational data workflows.
Chad Lynch serves as Smart Contracts Lead at Sapien. Lynch’s background in DeFi and smart contract security is important for Sapien’s onchain architecture.
The Sapien community consists of several different layers. The first layer includes contributors who complete tasks. These users contribute to the system through data labeling, evaluation or tasks requiring expertise.
The second layer includes validators. Validators evaluate the outputs produced by contributors according to defined rubrics and help form the quality consensus.
The third layer includes developers, institutions and AI teams. These parties can integrate Sapien’s PoQ infrastructure into their own data flows or AI quality control processes.
The SAPIEN token is positioned as the economic coordination tool of this community structure. Users join the system by staking, earn rewards as they provide quality contributions and can build a stronger reputation profile over time.
Frequently Asked Questions (FAQ)
Below are some frequently asked questions and answers about Sapien (SAPIEN):
- What is Sapien and when did it launch?: Sapien is a decentralized data protocol focused on producing verifiable human knowledge and high-quality training data for artificial intelligence systems. The SAPIEN token’s Token Generation Event took place on August 20, 2025.
- Who developed Sapien?: Sapien’s leadership team includes CEO Rowan Stone, CSO Trevor Koverko, CTO Kelly Ryan and Smart Contracts Lead Chad Lynch. The team consists of people experienced in crypto infrastructure, AI data systems, product development and smart contract security.
- What is the SAPIEN token used for?: The SAPIEN token is used for staking, contributor rewards, task access, quality assurance, the reputation system and governance processes in the future. The token is the main tool connecting data quality and economic incentives in the Sapien protocol.
- What problems does Sapien aim to solve?: Sapien aims to solve problems such as AI data quality, data source verification, measurement of human contribution, lack of transparency in centralized quality control systems and low-quality data production.
- What is Proof of Quality?: Proof of Quality is the quality verification system Sapien uses for subjective data and expert outputs. In this system, an output is scored by independent validators, a shared quality score is created and the result is connected to an onchain verifiable record.
- Which network does SAPIEN run on?: SAPIEN is an ERC-20 token that runs on the Base network. Base is an Ethereum-compatible Layer 2 network.
- When was SAPIEN coin listed?: The SAPIEN token’s TGE took place on August 20, 2025. Binance Alpha and Binance Futures trading started on the same date. The Binance spot listing was announced on November 6, 2025, with the SAPIEN/USDT, SAPIEN/USDC, SAPIEN/BNB and SAPIEN/TRY pairs.
- What is the SAPIEN token supply?: SAPIEN’s maximum supply has been set at 1,000,000,000 tokens. According to the tokenomics document, this supply is fixed and there is no inflationary new mint plan above 1 billion tokens.
For the latest information on Sapien, Proof of Quality and blockchain-based AI data verification projects, follow the JR Kripto Guide series.



